随着大语言模型(LLM)、生成式AI和边缘智能的普及,AI系统已从独立工具演变为深度依赖第三方组件的复杂生态:一个典型的AI应用可能包含开源框架(如TensorFlow)、预训练模型(如GPT-4 API)、数据标注工具(如LabelStudio)、容器镜像(如Docker Hub中的AI环境)以及云服务(如AWS SageMaker)。这种“组件拼接式”开发模式,使得AI系统的攻击面从代码本身扩展到整个供应链的每一个环节——2024年Check Point研究显示,针对AI供应链的攻击事件同比增长187%,其中预训练模型投毒、开源库后门、数据标注污染成为三大主要威胁。AI供应链安全治理,已成为保障AI可信性的核心命题。
一、AI供应链安全的独特挑战
AI系统的供应链风险与传统软件存在本质差异,其核心源于数据、模型、环境的深度耦合:
1. 数据供应链的“污染传导”
AI的决策依赖训练数据,而数据往往来自第三方供应商、众包平台或公开数据集。2023年,某自动驾驶公司因使用被篡改的道路图像数据集(含隐藏的交通标志错误标注),导致测试车辆误判红绿灯,直接延误上市进程。这类风险的隐蔽性在于:数据污染可能是低比例、针对性的(如仅修改0.1%的样本),但会通过模型训练放大为系统性错误,且难以通过传统代码审计发现。
2. 模型供应链的“黑箱依赖”
企业普遍使用预训练模型(如Hugging Face上的开源模型)或API服务(如OpenAI),但模型的训练过程、数据来源和参数设置通常不透明。2024年,一款广泛使用的开源图像分类模型被发现嵌入后门:当输入图像包含特定像素 pattern 时,模型会错误分类(如将“猫”识别为“狗”)。更严峻的是,模型即服务(MaaS)模式下,企业无法直接审计模型内部逻辑,只能依赖供应商的安全承诺。
3. 环境供应链的“链式风险”
AI系统的运行依赖容器、虚拟化工具和云基础设施。2023年,PyTorch官方镜像被发现包含恶意脚本,攻击者通过篡改镜像中的依赖库,窃取用户的训练数据和模型权重。这类风险的传导性极强:一个受污染的基础镜像可能被用于数十个AI项目,导致“一损俱损”的连锁反应。
二、AI供应链安全治理框架
针对上述挑战,提出AI供应链安全治理框架: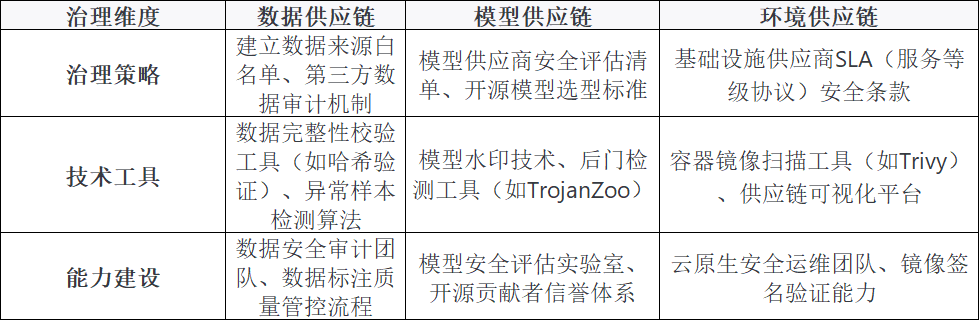
1. 数据供应链:从“来源可信”到“质量可控”
数据是AI的“燃料”,其安全需覆盖采集、标注、存储、使用全流程:
来源治理:建立供应商评估机制,优先选择通过ISO 27001认证的数据服务商;对公开数据集(如ImageNet、COCO),需验证其版权和完整性(如使用SHA-256哈希比对官方版本)。
标注管控:采用“双盲标注+交叉验证”流程,对敏感数据(如医疗影像)使用联邦学习技术,避免原始数据集中存储;同时引入AI辅助标注工具(如Amazon SageMaker Ground Truth),自动识别标注错误。
使用审计:记录数据的“血缘关系”(如数据从哪里来、被哪些模型使用),通过数据 lineage 工具(如Apache Atlas)追溯风险源头。
2. 模型供应链:从“依赖信任”到“可验证可信”
模型是AI的“核心引擎”,其安全需解决透明性不足、后门隐蔽的问题:
供应商管理:制定《AI模型供应商安全评估清单》,要求供应商提供模型训练日志、数据来源说明和安全测试报告;对MaaS服务,需明确数据隐私条款(如是否保留用户输入数据)。
开源模型审计:建立内部模型安全实验室,使用静态分析工具扫描模型代码,用动态测试工具检测后门;对高风险模型(如金融风控模型),需进行第三方安全认证。
模型防护:为自研模型添加数字水印(如在模型参数中嵌入不可见标识),用于追踪模型泄露;使用对抗训练技术增强模型对恶意输入的鲁棒性。
3. 环境供应链:从“被动防御”到“主动免疫”
环境是AI的“运行底座”,其安全需覆盖容器、镜像、云服务全栈:
镜像安全:使用私有镜像仓库(如Harbor)替代公共仓库,对所有镜像进行签名(如Docker Content Trust)和漏洞扫描(如Clair);建立镜像版本控制机制,禁止使用“latest”标签。
云基础设施:选择支持“零信任架构”的云服务商,启用VPC(虚拟私有云)隔离AI工作负载;对云存储中的模型和数据,使用端到端加密(如AWS KMS)。
供应链可视化:部署SBOM(软件物料清单)工具(如CycloneDX),自动生成AI系统的组件清单,实时监控组件的漏洞更新(如通过NVD漏洞数据库)。
三、能力发展建议:从“单点防护”到“体系化防御”
AI供应链安全治理不是一次性项目,而是持续迭代的能力建设过程,需从以下三方面突破:
1. 组织能力:建立跨职能团队
传统的“开发-安全”分离模式已不适用AI场景,需成立AI安全委员会,成员包括数据科学家、安全工程师、法务和采购人员:
数据科学家负责识别数据和模型的安全风险;
安全工程师负责工具落地和漏洞响应;
采购人员负责将安全要求纳入供应商合同。
2. 技术能力:拥抱MLSecOps
借鉴DevSecOps理念,构建MLSecOps流水线:将安全测试嵌入AI模型的训练、部署和迭代流程。例如:
训练阶段:自动扫描训练数据中的异常值;
部署阶段:检测模型是否存在后门;
运行阶段:监控模型输入输出的异常模式(如突然出现的错误分类)。
3. 生态能力:参与行业协作
AI供应链安全是全行业问题,需联合上下游共同应对:
加入开源安全组织(如OpenSSF),参与AI模型安全标准制定;
与供应商共享威胁情报,如发现某开源库存在漏洞,及时通知行业伙伴;
推动监管机构出台AI供应链安全法规(如欧盟AI法案已要求高风险AI系统提供供应链透明度报告)。
结语:AI安全的“新基建”
AI供应链安全治理,本质是为AI系统构建“可信底座”——当我们惊叹于AI生成内容的创造力时,更需关注其背后每一个组件的安全性。正如传统软件供应链安全推动了SBOM和DevSecOps的普及,AI供应链安全也将催生新的技术标准和治理模式。未来,只有那些能在“创新速度”和“安全可控”之间找到平衡的企业,才能真正释放AI的价值。
思考:当AI模型可以自主选择和调用第三方组件时,我们该如何设计“自我治理”的安全机制?这或许是下一代AI安全的核心命题。